 豫章小站
豫章小站最新在学习Python抓取网页时,遇到一个坑,同一个方法提取两个网页,有一个网页提取不到正确的信息。先贴原始的代码
url = 'https://xxxx.com/'
req = request.Request(url)
#设置cookie
cookie_str="xxxxxxxxxxxx"
req.add_header('cookie', cookie_str)
#设置请求头
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36')
resp = request.urlopen(req)
#resp.read().decode('unicode_escape')
rr=resp.read().decode('gbk')
getstr=BeautifulSoup(rr,'html.parser')
tr_list=getstr.select('tbody>tr')
tr_list这里获取不到正确的值,只有一行输出,明显不是正确的信息。

仔细查看核对了源码,确认是一样的,但确实有一个页面提取不到。只有上面所示一条不对的结果。
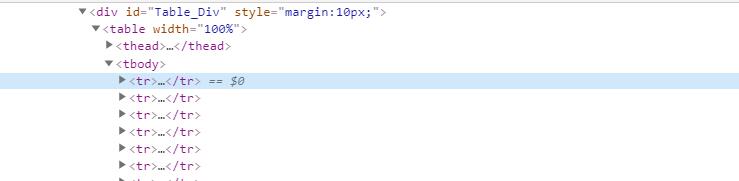
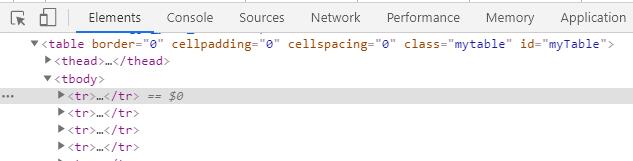
通过把getstr输出查看到问题,tbody马上就闭合了标签,但下面的tr又是正常输出的,所以结果只有一个。
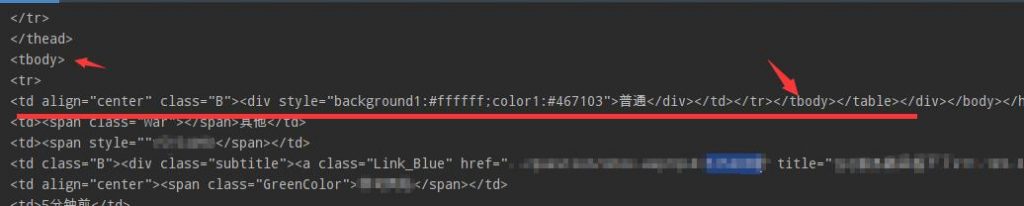
后面查看了一些资料,用lxml解决。
getstr = BeautifulSoup(rr, 'html.parser')
换成
getstr=BeautifulSoup(rr,'lxml')
lxml插件需要安装。https://www.lfd.uci.edu/~gohlke/pythonlibs/ 到这里下载到本地,cmd到下载文件路径下执行,whl为具体下的文件名称。
pip install lxml-4.5.0-cp38-cp38-win_amd64.whl
» 本文链接地址:https://mydns.vip/2698.html











最新评论