 豫章小站
豫章小站现象
作为一个站点有时候会去访问一下百度|google等第三方统计工具,查看一下有多少人访问自己的网站,看一看来源和关键词,但是最近在百度统计的进程查看到来源不是正规搜索引擎和网站,而是一些涉黄涉赌的网站来源,自己网站又和他们没有交换友链,查看他们的网站又没有自己的友链,查看来源很奇怪。
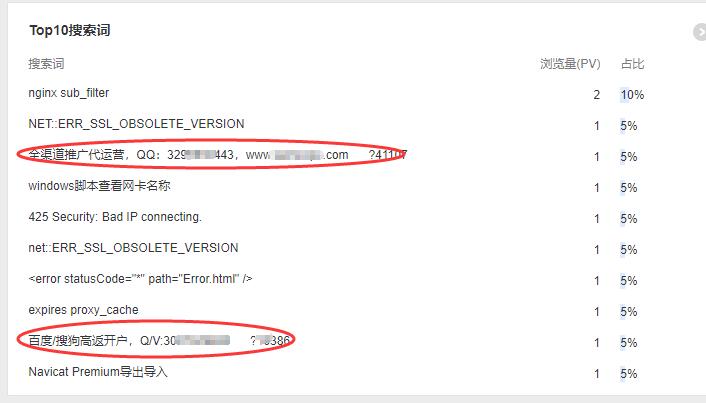
分析
这个问题之前也是处理过一个相同类似的问题,当时认为可能是对方使用主机的访问统计代码加到自己的网站统计中,但是这次查看对应的网站实际上根本没有对应的统计编码。
通过同事处理问题遇到一个相同的问题,发现了一个软件导致这个现象,具体软件地址http://www.niu5.com/soft/3.html ,就是利用的统计代码js提交,通过模拟提交的参数让统计网站上看起了似乎有很多人访问的样子,这样自己网站的seo优化就上去了,但是个人感觉然并卵,要是这样容易网站收录排名就上去了,那还有谁搞原创,好好维护网站,直接刷就是了。
统计js分析
百度统计的js
<script>
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "//hm.baidu.com/hm.js?bb3d32124**********p3962";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script> 之前已经分析过了,主要关键就是//hm.baidu.com/hm.js?后面的站点id,这个代表了你在百度统计平台的变化,对应访问也是提交到这个id的百度统计的站点中。现在我们来分析一下这段js的具体作用。实质上是往页面中引入hm.baidu.com/h.js的这段代码,该代码的内容会根据后面的参数有所不同,h.js?后面的参数就是你在百度统计里的id,获取该h.js代码的同时,百度统计会往你的浏览器写入一个名字为“HMACCOUNT”的cookie,该cookie的过期时间为2038年,所以只要你没有清空浏览器cookie,基本就永不过期。h.js被下载后,便执行其脚本获取一些浏览器相关信息和访问来源,获取的信息包括屏幕尺寸、颜色深度、flash版本、用户语言等。从js代码中可以得到,所有参数包括这些:”cc,cf,ci,ck,cl,cm,cp,cw,ds,ep,et,fl,ja,ln,lo,lt,nv,rnd,sb,se,si,st,su,sw,sse,v”。这些参数的意义大致如下:
cc: 不知道,一般为1
cf:url参数hmsr的值
ci:url参数hmci的值
ck:是否支持cookie 1:0
cl:颜色深度 如 “32-bit”
cm:url参数hmmd的值
cp:url参数hmpl的值
cw:url参数hmkw的值
ds:屏幕尺寸,如 ’1024×768′
ep:初始值为’0′,时间变量,反映页面停留时间,格式大概是:现在时间-载入时间+“,”+另一个很小的时间值
et:初始值为’0′,如果ep时间变量不是0的话,它会变成其他
fl:flash版本
ja:java支持 1:0
ln:语言 zh-cn
lo: 不知道,一般为0
lt:日期 time.time(),如“1327847756”, 在首次请求没有
nv: 不知道,一般为1或者0
rnd:十位随机数字
sb:如果是360se浏览器该值等于‘17’
se: 和搜索引擎相关
si:统计代码id
st:
su:上一页document.referrer
sw: 不知道,估计和搜索引擎有关,一般为空
sse:不知道,估计和搜索引擎有关,一般为空
v:统计代码的版本 ,目前该值为“1.0.17”以上是之前的分析内容。当这些参数都设置完毕了(有些参数并没有赋值),筛选出已经赋值了的参数,并作为hm.baidu.com/hm.gif的参数拼凑出一个url,如:https://hm.baidu.com/hm.gif?hca=43D6B13F7AFD6EAA&cc=1&ck=1&cl=24-bit&ds=1600x900&vl=757&ep=1208736%2C120506&et=3&ja=0&ln=zh-cn&lo=0<=1609221289&rnd=715135271&si=15caeaa6c5b6d98c57a013703ae23357&su=https%3A%2F%2Fwww.lnmpweb.cn%2F%3Fs%3D%25E7%259F%25A5%25E4%25B9%258E&v=1.2.80&lv=3&sn=14043&r=0&ww=1600&u=https%3A%2F%2Fwww.lnmpweb.cn%2Farchives%2F6766 。然后请求该图片。百度统计服务端,通过接收到这个请求,并从这个图片的网址附带的参数获取相关信息,记录访客访问记录;当页面被用户关闭的时候,同样会触发一次请求hm.gif的过程,但这个过程不是所有浏览器和所有关闭动作都支持。
通过抓包 可以发现,浏览器总共向服务器端发送了4次请求:
- 1.请求一段js脚本。
- 2.加载完毕时候出发一次请求,并传递参数
- 3.退出页面时候,发出一次请求,并传递参数,与上面对比,发现ep参数有变化。百度统计是基于cookie的,当请求js脚本的时候,会在你电脑里保存一个永久cookie,该cookie作为你的用户标识。同时发现,但退出时候参数ep从最开始的0变为了“7289%2C115”,转义后是“7289,115”这是两个毫秒单位,即7.2秒和0.1秒的意思。同时前两次请求hm.gif的时候lt参数(时间,javascript:(new Date).getTime())是不变的。rnd随机数每次都变。
- 根据这个原理写了一个python脚本实现了相同功能。之前参考的文章的脚本没法执行,自己修改一下可以使用
import requests
from urllib.parse import quote,urlencode
import time
import random
class Baidu:
Referer='http://www.xxxxx.com' #来源页面
BaiduID='0ff308da7f65d64caca220f1321fe0dd'
TargetPage = "https://www.baidu.com/link?url=1vrjw1L5ROSBd2PJPeG_jkZGGLbnJJs254PE9vgytVm&wd=2222&eqid=a3a9b9890001a3f3000000065fe9a391"
Hjs="https://hm.baidu.com/hm.js?"
Hgif="https://hm.baidu.com/hm.gif?"
UserAgent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
MyData={'cc':'1','ck':'1','cl':'16-bit','ds':'1920x1080','vl':'382','ja':'0','lv':'1','ln':'zh-cn','lo':'0','v':'1.2.61'}
def __init__(self,baiduID, targetPage=None, refererPage=None):
self.Referer=refererPage
self.BaiduID=baiduID
self.targetPage = targetPage
self.MyData['si']=self.BaiduID
# self.MyData['su']=urllib.parse.quote(self.Referer)
def run(self,timeouts=5):
requests.packages.urllib3.disable_warnings()
requests.adapters.DEFAULT_RETRIES = 15
rquest_session = requests.Session()
headers = {}
headers['User-Agent'] = self.UserAgent
headers['Referer'] = self.Referer
headers['Connection'] = "Keep-Alive"
headers['Accept'] = "image/webp,*/*"
headers['Host'] = "hm.baidu.com"
# self.MyData['sn']= int(time.time()) % 65535
# self.MyData['ep']='17211,100'
# self.MyData['lt']=int(time.time())
# self.MyData['et']='3'
#第0次请求
self.MyData['sn']= int(time.time()) % 65535
self.MyData['ep']='17211,100'
self.MyData['lt']=int(time.time())
self.MyData['rnd']=int(random.random()*2147483647 )
self.MyData['et']='3'
print(self.Hgif+urlencode(self.MyData))
#第一次请求
headers['Referer'] = self.targetPage
headers['Accept'] = "*/*"
rquest_session.get(self.Hjs+self.BaiduID, headers=headers, verify=False, timeout=timeouts)
print(self.Hjs+self.BaiduID)
time.sleep(1)
# self.MyData['u']= urllib.parse.quote(self.Site)
# self.MyData['sn']= "15544"
del self.MyData['lt']
del self.MyData['ep']
self.MyData['tt']="张三测试"
self.MyData['et']='0'
# self.MyData['ct']='!!'
self.MyData['vl']='227'
self.MyData['sn']= int(time.time()) % 65535
self.MyData['rnd']=int(random.random()*2147483647 )
self.MyData['su']=self.Referer
# self.MyData['lt']=int(time.time())
headers['Accept'] = "image/webp,*/*"
fullurl=self.Hgif+urlencode(self.MyData)+"&ct=!!"
print(fullurl)
#第二次请求
rquest_session.get(fullurl, headers=headers, verify=False, timeout=timeouts)
if __name__ =="__main__":
a=Baidu('15caeaa6c5b6d98c57a013703ae23357','http://www.123456.com/?www.qq.com',"https://cn.bing.com/search?q=张三测试")
a.run()
# 15caeaa6c5b6d98c57a013703ae23357 百度统计的id
# http://www.123456.com/?www.qq.com 入口页面
# https://cn.bing.com/search?q=张三测试 来源参考:https://www.cnblogs.com/devour-world/p/7851925.html
所以最终处理结论:重新更换统计代码。
» 本文链接地址:https://mydns.vip/3592.html


















最新评论
学习学习
nihao